本文介绍了 5 大常用机械进修模型类型: 鸠合进修算法,注释型算法,聚类算法,降维算法 ,相似性算法,并简要介绍了每种类型中最普遍使用的算法模型。我们进展本文能够做到以下三点: 1、应用性。 涉及到应用问题时,常识的普适性显然非常主要。所以我们进展经由给出模型的一样类别,让你更好地认识这些模型该当若何应用。 2、相关性。 本文并不包罗所有的机械进修模型,好比Naïve Bayes(朴实贝叶斯)和SVM这种传统算法,在本文中将会被更好的算法所庖代。 3、可消化性 。对于数学根蒂较微弱的读者而言,过多地注释算法会让这篇文章的可读性变差,更况且,你能够在网上找到无数教我们实现这些模型的资源。是以,为了避免本文变得无聊,我们将会把目光放在分歧类型的模型的应用上。 01 集成进修算法
(随机丛林XGBoost, LightGBM, CatBoost)
什么是集成进修算法?
为了懂得什么是集成进修算法,首先,你需要知道什么是集成进修。集成 进修是一种同时使用多个模型,以达到比使用单一模型更好的机能的方式。 我们向一个班里的学生提出一个数学问题。他们有两种解答体式:合作解答和单人解答。生活经验敷陈我们,若是全班同窗一路合作,那么学生之间能够互相搜检,协作解决问题,并最终给出一个独一的谜底。然而单人作答就没有这种搜检的..了——即使他/她的谜底错了,也没有人能帮他/她磨练。 这里的全班协作就雷同于一个集成 进修算法,即由几个较小的算法同时工作,并形成最终的谜底。 应用
集成进修算法首要应用于回来和分类问题或监视进修问题。因为其固有的性质,集成进修算法优于所有传统的机械进修算法,包罗Naïve Bayes、SVM和决议树。 算法
XGBoost: 雷同于梯度提拔(GradientBoost)算法,但添加了剪枝,Newton Boosting,随机化参数等功能,因而比梯度提拔更壮大。LightGBM: 行使基于梯度的单边采样(GOSS)手艺过滤数据的一种提拔算法,今朝实验已经证实比XGBoost更快,且有时更正确。 02 注释型算法
(线性回来、逻辑回来、SHAP、LIME)
什么是注释型算法?
注释型算法使我们可以识别和懂得究竟有统计学意义的变量。是以,与其建立模型来展望响应变量的值,不如建立注释性模型来匡助我们懂得模型中变量之间的关系。 而从回来的角度来看,人们往往强调统计学上显著的变量,这是因为对于从一个整体中提掏出的样本数据,若是想对样本做出结论,首先必需确保变量拥有充沛的显著性,并由此做出有把握的假设。 应用
注释性模型平日用于需要作出注释的场景。好比展示 「为什么 」做出某个决意,或许注释两个或多个变量之间「若何」互相关系。 在实践中,你的机械进修模型的可注释性与机械进修模型自己的机能一般主要。若是你不克注释一个模型是若何工作的,那么这个模型就很难守信于人,天然也就不会被人们应用。 算法
线性回来: 若是 2 个或许多个变量之间存在“线性关系”,就能够经由汗青数据,竖立变量之间的有效“模型”,来展望将来的变量究竟。例如,y = B0 + B1 * x。 Logistic回来: 逻辑回来首要解决二分类问题,用来透露某件事情发生的或者性。 注释机械进修模型的算法:
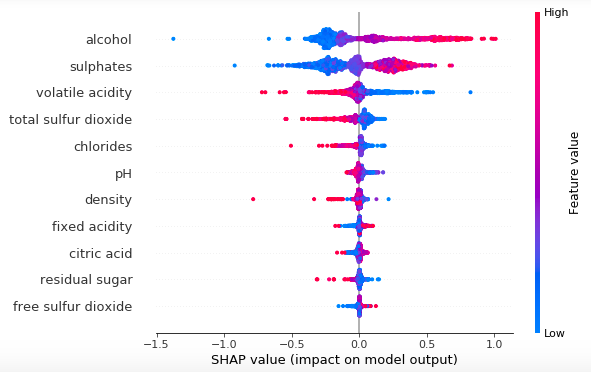
SHAP: 即来自博弈论的沙普利加息争释,实际是将输出值归因到每一个特征的shapely值上,依此来权衡特征对最终输出值的影响。 LIME: LIME算法是Marco Tulio Ribeiro2016年揭橥的论文《"Why Should I Trust You?" Explaining the Predictions of Any Classifier》中介绍的局部可注释性模型算法。该算法首要用于文本类与图像类的模型中。03 聚类算法
(k-Means,分层聚类法)
什么是聚类算法?
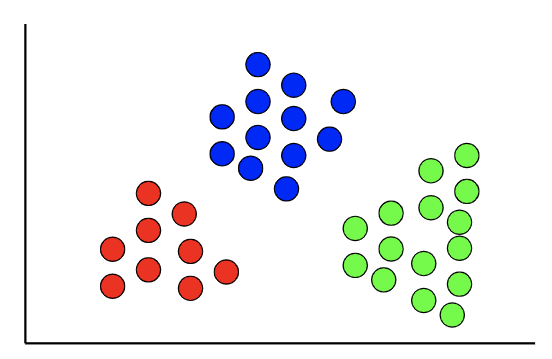
聚类算法是用来进行聚类剖析的一项无监视进修义务,平日需要将数据分组到聚类中。与监视进修的已知方针变量分歧,聚类剖析中平日没有方针变量。 应用
聚类算法能够用于发现数据的天然模式和趋势。聚类剖析在EDA阶段非经常见,因为能够获得更多的数据信息。 同样,聚类算法能帮你识别一组数据中的分歧部门。一个常见的聚类细分是对用户/客户的细分。 算法
K-means聚类: K均值聚类算法是先随机拔取K个对象作为初始的聚类中心。然后较量每个对象与各个种子聚类中心之间的距离,把每个对象分派给距离它比来的聚类中心。 条理聚类: 经由较量分歧类别数据点间的相似度来建立一棵有条理的嵌套聚类树。04 降维算法
(PCA, LDA)
什么是降维算法?
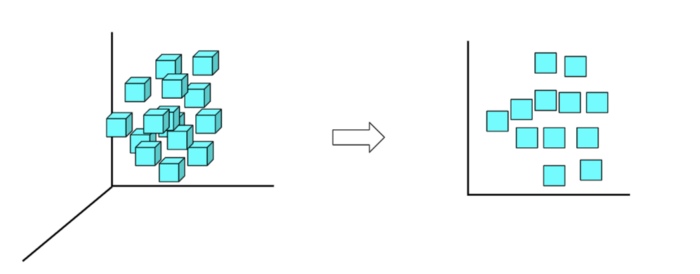
降维算法是指削减数据集输入变量(或特征变量)数量的手艺。素质上来说降维是用来解决“维度谩骂”的。(维度谩骂:跟着维度(输入变量的数量)的增加,空间的体积呈指数级增进,最终导致数据稀少。) 应用
降维手艺适用于好多情形,好比:当数据集中的特征好多而实际需要的输入变量很少时,或许当ML模型过度拟合数据时,都能够使用降维手艺。 算法
主成分剖析(PCA) :一种使用最普遍的数据降维算法。PCA的首要思惟是将n维特征映射到k维上,这k维是在原有n维特征的根蒂上从新组织出来的,全新的正交特征。 线性判别剖析(LDA): 用于在有两个以上的类时进行线性分类。
05 相似性算法
(KNN、欧几里得距离、余弦、列文斯坦、Jaro-Winkler、SVD...)
什么是相似性算法?
相似性算法是指那些较量记录/节点/数据点/文本对的相似性的算法。所以相似性算法包含很多种类,例若有对照两个数据点之间距离的相似性算法,如欧氏距离;也有较量文原形似性的相似性算法,如列文斯坦算法。 应用
相似性算法也能够用于各类场景,但在与“介绍”相关的应用上示意尤为出彩,好比用来决意: 凭据你之前的阅读情形,Medium应该向你介绍哪些文章? 算法
K临近: 经由在整个练习集上搜刮与该数据点最相似的 K 个实例(近邻)而且总结这 K 个实例的输出变量,从而得出展望究竟。欧几里德距离: 一个平日采用的距离界说,指在m维空间中两个点之间的真实距离,或许向量的天然长度(即该点到原点的距离)。余弦相似度: 行使向量空间中两个向量夹角间的余弦值权衡两个个别之间差别的巨细,余弦值接近1,夹角趋于0,表明两个向量越相似,余弦值接近于0,夹角趋于90度,表明两个向量越不相似。列文施泰因算法: 指两个字串之间,由一个转成另一个所需的起码编纂把持次数。Jaro-Winkler算法: Jaro–Winkler distance 适合于较短的字符之间较量相似度。0分透露没有任何相似度,1分则代表完全成家。奇异值分化(SVD)(不完全属于相似性算法,但与相似性有间接关系): 界说一个m×n的矩阵A的SVD为:A=UΣVT ,个中U是一个m×m的矩阵,Σ是一个m×n的矩阵,除了主对角线上的元素以外全为0,主对角线上的每个元素都称为奇异值,V是一个n×n的矩阵。U和V都是酉矩阵,即知足UTU=I,VTV=I。此次终于彻底懂得了SVD奇异值分化 以上就是对当前主流的机械进修算法的总结,进展本文能匡助你更好地认识各类ML模型以及它们的应用场景。当然,纸上得来终觉浅,若是本文使你有所收获,那就请起头你的应用之路吧,看看你能用ML解决什么问题! 参考链接: